10月23日
一个简单的Python数据处理案例
---从电影票房案例熟悉数据处理流程
PYTHON
文 /锡安
排版/Adan
01
基本步骤
数据预处理
数据的增删改查
分析模型搭建
可视化
...
02
数据预处理
初始数据可能是杂乱的数据,并且有较多的空值等问题,因此要对数据进行清洗以便接下来的分析。
在分析前我们先看一下本次案例的原始数据,打开csv文件,可以看到数据是由多个特征得到的,包含电影的色彩、导演等等信息,但是也注意到文件中有一些空值,这会对我们后续的分析造成影响。因此预处理是十分有必要的。

首先导入处理分析会用到的模块:
import pandas as pd
import matplotlib.pyplot as plt
接下来采用pandas的read_csv模块来读取我们需要的文件,因为程序和csv文件在同一文件夹下,因此我们只需要文件名不需要添加地址,然后,采用.shap的方法我们可以看到数据的维度为(5043, 28),即数据有5043行,28列,数据量也是比较大的::
#加载数据
data=pd.read_csv('movie_metadata.csv')
#查看维度
print('数据形状:',data.shape)
接下来,
可以使用head()看一下具体的数据(前5行):
#input:
print(data.head())
#output:
color ... movie_facebook_likes
0 Color ... 33000
1 Color ... 0
2 Color ... 85000
3 Color ... 164000
4 NaN ... 0
[5 rows x 28 columns]
由显示出的数据可以看到 4 行出现了NaN空值,因此我们首先要先对空值进行处理。
对于表格中空值的处理可以采用dropna()方法,这里我们选择默认关键字即只要含有NaN的行即除去,打印处理后的结构可以看到含有NaN的第四行即被去除。
#input
data=data.dropna()
print(data.head())
#output
color ... movie_facebook_likes
0 Color ... 33000
1 Color ... 0
2 Color ... 85000
3 Color ... 164000
5 Color ... 24000
[5 rows x 28 columns]
03
数据分析
查看导演的票房收入并排序:
#Input:
group_director=data.groupby(by='director_name')['gross'].sum()
print(group_director.sort_values(ascending=False))
#Output:
director_name
Steven Spielberg 4.114233e+09
Peter Jackson 2.289968e+09
Michael Bay 2.231243e+09
Tim Burton 2.071275e+09
Sam Raimi 2.049549e+09
James Cameron 1.948126e+09
哦嚯,Steven Spielberg遥遥领先

#成功人士的微笑
查看各位主演的票房收入:
#Input:
group_actor=data.groupby('actor_1_name')['gross'].sum()
print(group_actor.sort_values(ascending=False))
#Output
actor_1_name
Johnny Depp 3.714789e+09
Harrison Ford 3.391556e+09
Tom Hanks 3.264559e+09
Tom Cruise 2.987622e+09
J.K. Simmons 2.856407e+09
Johnny Depp 险胜Harrison Ford啊。

突然骄傲,插会儿腰~
接下来,哪对导演和演员cp(合作)可以获得更高票房?
可以先将导演名进行分组,在将其导演名下的演员进行分组,最后使用聚合函数sum()将其票房进行累加即可。
#导演主演+票房收入
group_act_dir=data.groupby(by=['director_name','actor_1_name'])['gross'].sum()
print(group_act_dir.sort_values(ascending=False))
#Output
director_name actor_1_name
Joss Whedon Chris Hemsworth 1.705551e+09
Sam Raimi J.K. Simmons 1.485313e+09
Gore Verbinski Johnny Depp 1.250323e+09
好了,
恭喜导演Joss Whedon与演员Chris Hemsworth 成功获得最佳CP
那么问题来了,这对CP的最佳影片是哪个?
在SQL中我们可以采用简单的
select*****from***where***来进行查询
在pandas中想要实现sql的查询语句也不难:
#Input
act_dir=data[(data['director_name']=='Joss Whedon')& (data['actor_1_name']=='Chris Hemsworth')]
print(act_dir['movie_title'])
#output
8 Avengers: Age of Ultron
17 The Avengers
794 The Avengers
嗯,果然是我爱的复仇者联盟

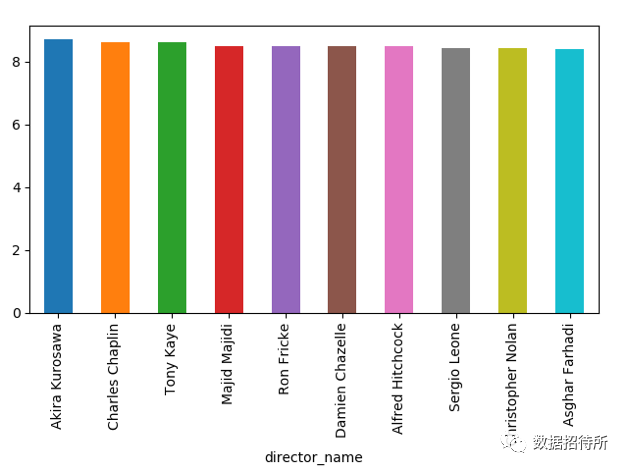
最后,查看imdb评分最高的导演是哪几位,我们选出其前十并进行绘图,这里用pandas的Series数组直接进行绘图很方便。
#Input:
director_mean=data.groupby('director_name')['imdb_score'].mean()
top_10=director_mean.sort_values(ascending=False)[:10]
plt.figure()
top_10.plot(kind='bar')
plt.show()
#Output:
04
最后
MOVIE
这个简单的案例包含了数据分析的基本内容:数据的加载,预处理,分组,排序、可视化等等。
SQL中简单的查询语句在Python中的实现有助于对数据进行进一步解析,而数据的预处理仍有许多知识需要在实际案例中不断学习和练习。

扫码关注我们
微信号 : WAY2AI


