不知不觉中,《英雄联盟》已经火到第10个年头了,除了《魔兽世界》,好像还真没这么一款网游能够这样经久不衰。正逢S9英雄联盟全球总决赛,有时间的话大伙可以去观看一下比赛,感受一下电竞的那种紧张、刺激,当然还有喜悦和失落...关键是你能熬夜,一局马上要开始了
![]()
......
听说今天是程序员日
![]()
,先感谢一下世界上所有的程序猿们,是你们的代码让这个世界变得更加精彩,而人类的未来“智能机器”时代也会在他们的代码中悄悄走来.......好像跟我这个业余的没多大关系,好吧,趁今天这么好的日子写个爬虫玩玩,目标是爬取《英雄联盟》全英雄信息,全英雄皮肤,全英雄语音,全英雄故事。低调一点,下面就进入正题。
打开《英雄联盟》官网英雄资料库:
https://lol.qq.com/data/info-heros.shtml
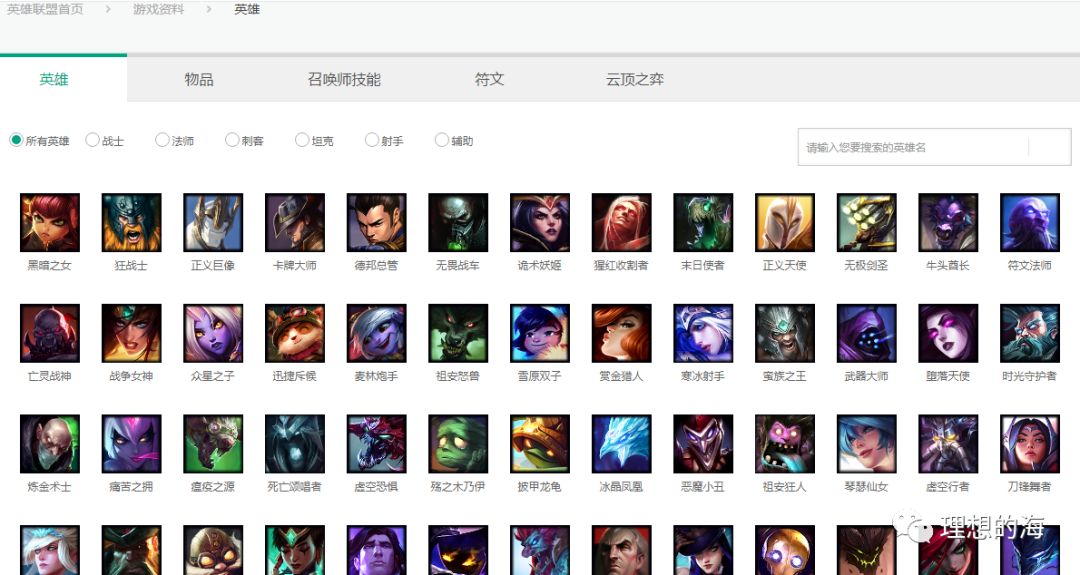
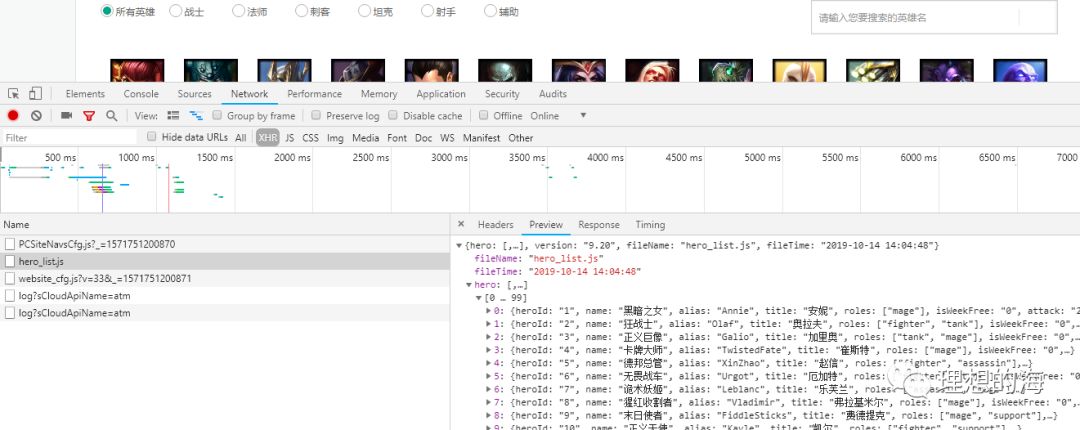
老规矩,按下F12进入调试模式,在"network"选项卡中选择"XHR",然后刷新页面,会看到有hero_list.js这个文件,它就是英雄列表数据,拿下来后是一个json即字典,在这里可以获取到英雄的ID号,英雄中英文名字及语音链接。重点记录英雄的ID,因为后面爬英雄皮肤,背景故事等都要用到。
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js' #英雄列表接口 headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Origin': 'https://lol.qq.com', 'Referer': 'https://lol.qq.com/data/info-heros.shtml', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36' }hero_list = get_response(url,headers).json()['hero']for hero in hero_list: hero_name = hero['name'] #英雄名称,如狂战士 cnname = hero['title'] #英雄的中文名,如安妮 enname = hero['alias'] #英雄英文名 hero_id = hero['heroId'] #英雄ID接下来要获取英雄的皮肤,从英雄列表页选择一个英雄进入详情页,这里以安妮为例...
可以在右下角看到该英雄有若干个皮肤,可以切换查看,我们还是打开调试,看加载了什么文件。
没错,又是一个json文件1.js,它里面就包含英雄的皮肤列表"skins",不用说皮肤数据肯定就在其中。
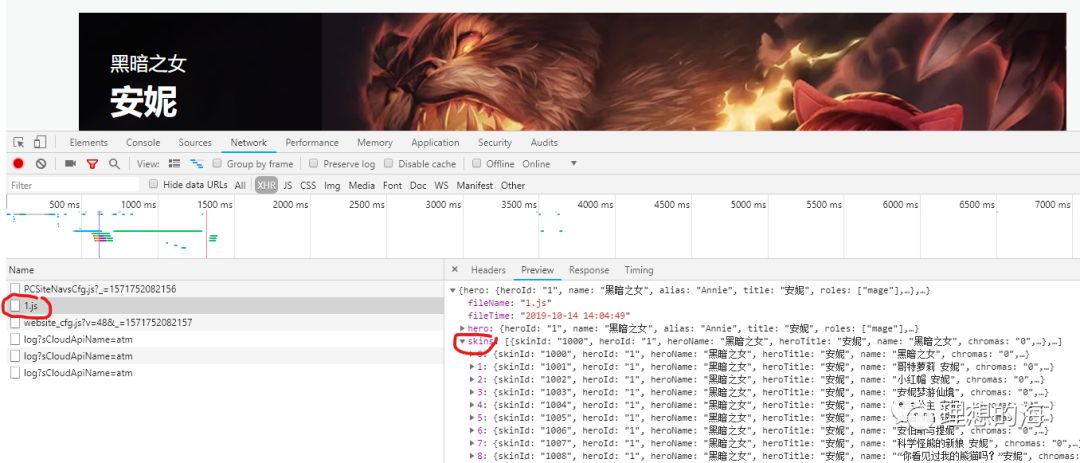
这里需要跟商场上在售皮肤做对比,发现这里面很多皮肤是线上没有的,说明这款皮肤还没有制作完成或还没上线销售,所以相应地就不会有皮肤的链接,程序中需要加一个判断,把没链接的皮肤T出来并作出提示
skin_link =f'https://game.gtimg.cn/images/lol/act/img/js/hero/{hero_id}.js' #英雄皮肤json headers = { 'Origin': 'https://lol.qq.com', 'Referer': f'https://lol.qq.com/data/info-defail.shtml?id={hero_id}', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'} skin_list = get_response(skin_link,headers).json()['skins'] if not os.path.exists(path+'/'+hero_name+'-'+cnname+'/'+'英雄皮肤'+'/'): os.makedirs(path+'/'+hero_name+'-'+cnname+'/'+'英雄皮肤'+'/') for i in skin_list: skin_url = i.get("mainImg") skin_name = i['name'] try: response = get_response(skin_url,headers) print(f'正在保存"{skin_name}"皮肤') with open (path+'/'+hero_name+'-'+cnname+'/'+'英雄皮肤'+'/'+skin_name+'.jpg','wb') as f: f.write(response.content) except: print(f'【{skin_name}】皮肤暂未上架销售') 好吧,基本信息,语音,皮肤都有了,接下来就是英雄的背景故事了,在我看来,这才是最重要的,每个英雄都来自不同的星系,而之所以能成为英雄,肯定有非常精彩的故事,闲暇之余就当看小说吧,也不错。
在“英雄联盟宇宙”这个网页:https://yz.lol.qq.com/zh_CN/champions/,很奇怪为什么称为宇宙,看了几页才明白这是一个英雄探索页面,在这里你可以探索你喜欢的英雄的一切信息,包括你不并不知道的如蛮王跟艾希其实是一对,亚索的徒弟是岩雀等等。不多说,开干。


有点像小说的味道哦,在调试页面同样是几个Json数据,顺手拿下提取就是了,真的是So easy!
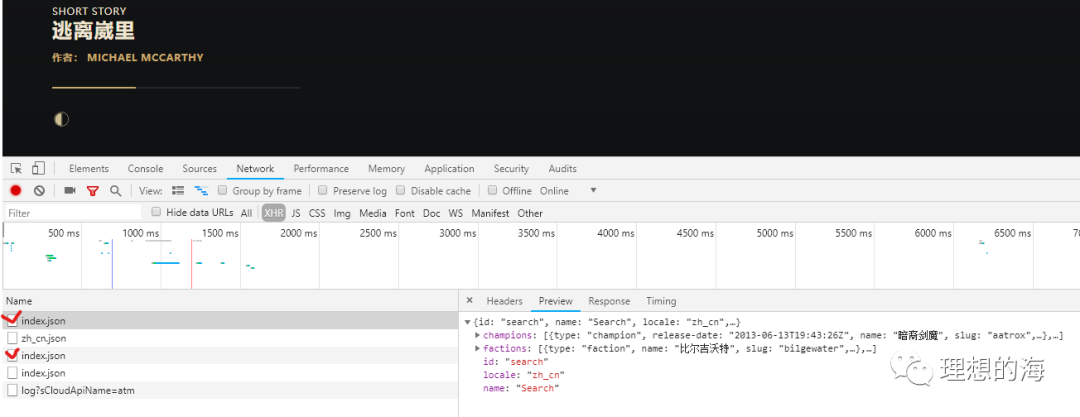
def get_hero_biog(): biog_link = f'https://yz.lol.qq.com/v1/zh_cn/champions/{enname.lower()}/index.json' story_link = f'https://yz.lol.qq.com/v1/zh_cn/story/{enname.lower()}-color-story/index.json' headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36', 'Referer': f'https://yz.lol.qq.com/zh_CN/story/champion/{enname.lower()}/'} biog_res = get_response(biog_link,headers) biog = biog_res.json()['champion']['biography'] fulls = biog['full'] shorts = biog['short'] quotes = biog['quote'] full = re.sub('[a-z\<\/\>]','',fulls) short = re.sub('[a-z\<\/\>]','',shorts) quote = re.sub('[a-z\<\/\>]','',quotes) with open (path+'/'+hero_name+'-'+cnname+'/'+'英雄传记.txt','w+',encoding = 'utf-8') as f: f.write (full+'\n'+short+'\n'+quote+'\n') story_res = get_response(story_link,headers) try: title = story_res.json()['story']['title'] story = story_res.json()['story']['story-sections'][0]['story-subsections'][0] contents = story ['content'] content = re.sub ('[a-z\<\/\>\&\;]','',contents) with open (path+'/'+hero_name+'-'+cnname+'/'+'英雄故事.txt','w+',encoding = 'utf-8') as f: f.write('《'+title+'》'+'\n'+content) except: print(f'{cnname}的故事还没有流传开来哦')全部爬下来的效果图:
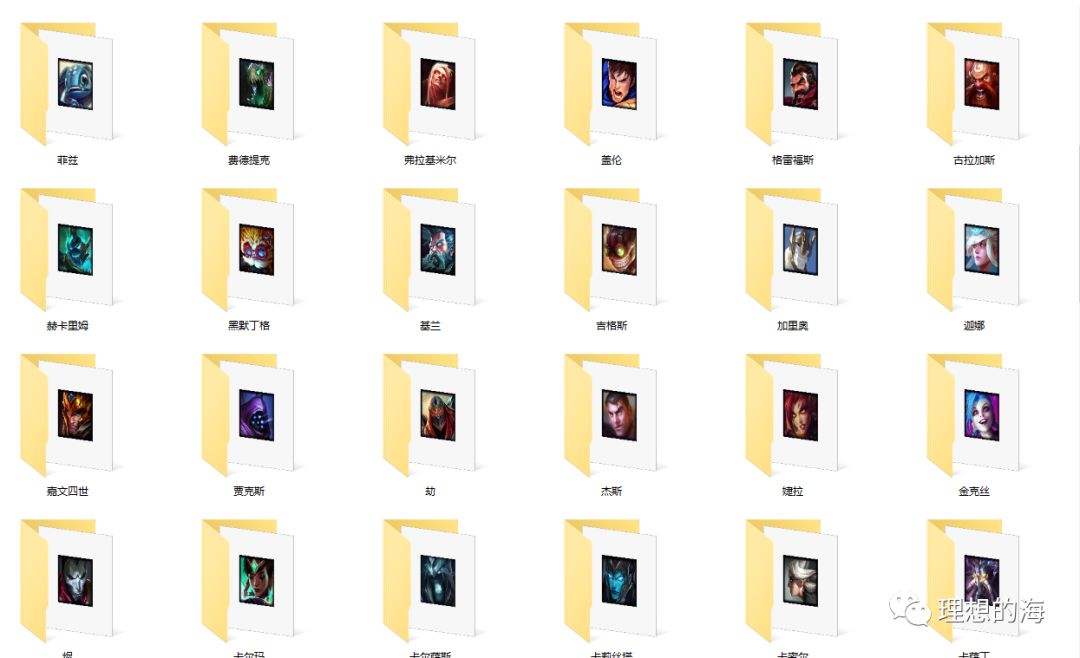

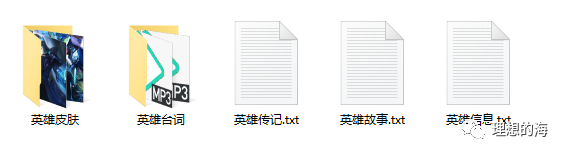

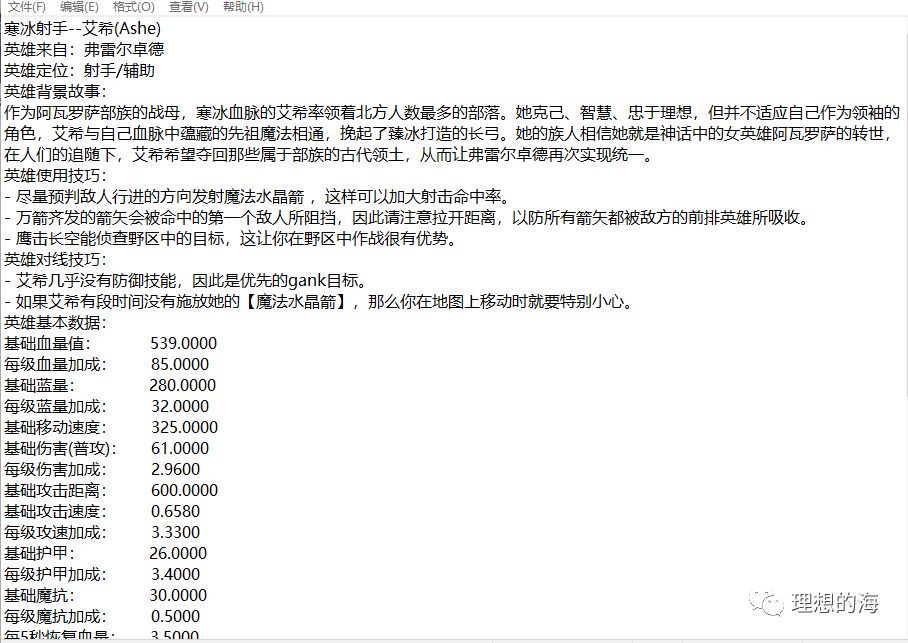


如果你会UI的话制作一款英雄数据查询工具是不错的选择,而我想做根本没有时间滴。
文中涉及的代码下载链接:
链接:https://pan.baidu.com/s/1SFV2cGc8hK1qJFEV8964kQ
提取码:f1s8
声明:本程序仅作为技术学习交流,请不要用于商业获利,如有该行为导致的法律问题,本人概不负责!
当然你还可以来个关注!



