关注Alfred数据室的数据分析爱好者们一直都在给Alfred数据室留言,问我们的数据是如何获取的,又是通过什么方法进行分析的,并且强烈要求Alfred数据室就此开一门数据科学的课程。
应大家的要求,Alfred数据室经过仔细的课程研究和设计,在严格确保课程质量的前提下,将陆续推出《实战玩转数据科学》系列课程!该系列课程分为数据获取、数据分析、大数据分析三个部分,从如何获取数据、怎么分析数据、通过什么方法分析海量数据三方面带领大家玩转数据分析。
在1024程序员节的今天,我们推出了该系列课程的数据获取部分子课程:《实战玩转Python爬虫》。

什么是Python爬虫?如何快速获取到有用的公开数据用以分析?学习Python爬虫需要储备哪些技能?《实战玩转Python爬虫》这门课程都涉及到哪些知识点,有什么特色呢?
如何快速获取公开数据
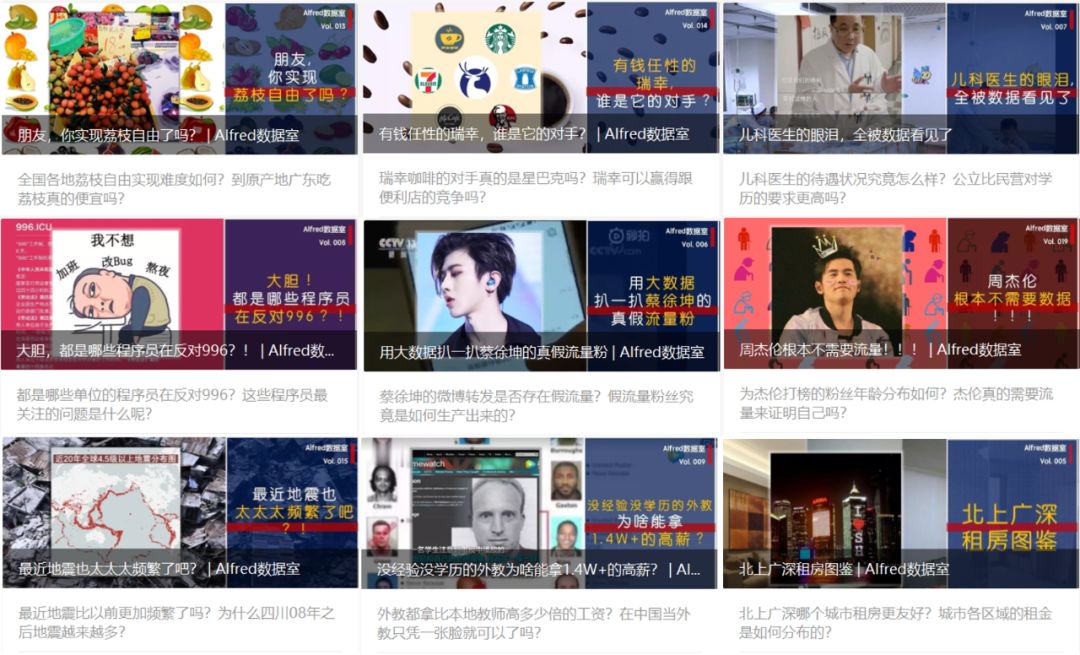
做《北上广深租房图鉴》时,我们获取了链家网北上广深四个城市的105258条租房数据,向大家展示一线城市的租房生态;
做《用大数据扒一扒蔡徐坤的真假流量粉》时,我们获取了蔡徐坤新浪微博《再见,“任性的”千千…》的10万条转发数据,带大家一探一线流量小生的微博数据真假;
做《儿科医生的眼泪,全被数据看见了》时,我们获取了丁香人才网10950条涵盖儿科、内科、外科、妇产科、眼科的招聘数据,从横纵两向看看儿科医生的真实处境;
做《大胆,都是哪些程序员在反对996》时,我们获取了10037条GitHub repos issues页面下的评论数据,以及39987条star了该repos的程序员GitHub个人信息数据,来看看来自不同公司的大家吐槽的点都在哪里;
做《最近地震也太太太频繁了吧》时,我们获取了美国地质勘探局(USGS)2000年以来全球发生的所有4.5级以上地震数据131865条,解答近来地震是不是比以往更频繁了的疑问;
做《周杰伦根本不需要流量》时,我们获取了新浪微博周杰伦超话和蔡徐坤超话新进粉丝30000多条数据,以全网最快速度做出打榜杰迷粉丝画像,看看这次“夕阳红”团建活动中的你我他到底是怎样的存在。
数据是怎么来的?
当然,过去所做项目中数以十万、百万计的数据是绝不可能靠手动获取回来的,这其中所使用的工具就是Python爬虫。
什么是Python爬虫,它就是使用Python这门程序语言去自动抓取、采集网上公开数据的脚本,可以帮助我们快速地获取到想要的公开数据。它具有高速爬行和定向抓取等特定,这也让它成为各行各业工作中获取数据不可缺少的帮手。

Alfred数据室通过问卷抽样、市场调查等形式了解了同学们学习Python爬虫的痛点难点后,经过三个月不间断的课程设计和打磨,推出《实战玩转Python爬虫》这门课程,帮助大家以最有效的方式掌握Python爬虫。
本次课程作为《实战玩转数据科学》系列课程的数据获取部分,《实战玩转python爬虫》将以丰富的原创实战案例,带领大家体验利用Python爬虫获取数据的三个标准流程(数据获取—数据解析—数据储存),让同学们直接从实战入门数据科学领域,合理获取到各方面公开数据。
课程特点及疑问解答
你:为什么我学了很久Python编程还是不会获取数据?
众所周知,Python爬虫不是一门单一技术,而是一门集合了Python语言、Web 前端、计算机网络、数据库等知识的综合性技术,如果没有清晰的学习路径、明确的实战目标,很容易就由“从入门到进阶”变成了“从入门到放弃”。
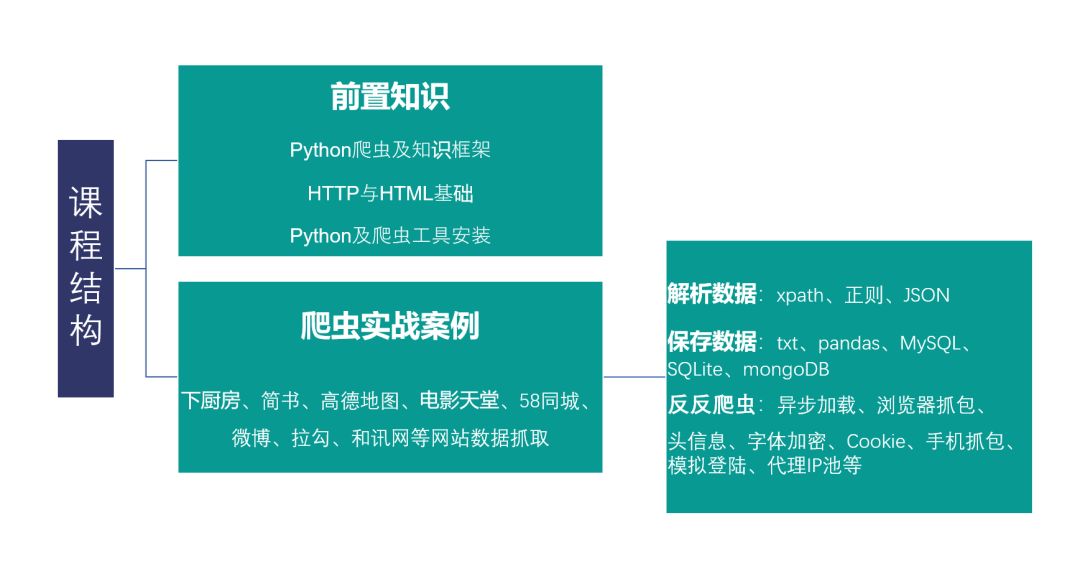
所以,为了让大家顺畅地学习Python爬虫,顺利地获取到数据,本课程以Python爬虫实战项目为导向,以相关的基础知识为支撑,为大家提供了一个清晰的学习路径和知识框架,从逐步深入的实战项目出发,为大家展示实战中会遇到的各种坑,以及填坑所需要的知识,让大家在项目中掌握综合性知识,降低学习成本。
你:我学过那么多教程的项目,怎么还是写不好自己的爬虫项目?
市面上很多教程都呈现出千篇一律的样式,实战项目雷同率可见一斑,这样的学习过程不仅浪费宝贵时间,还很难进行举一反三。

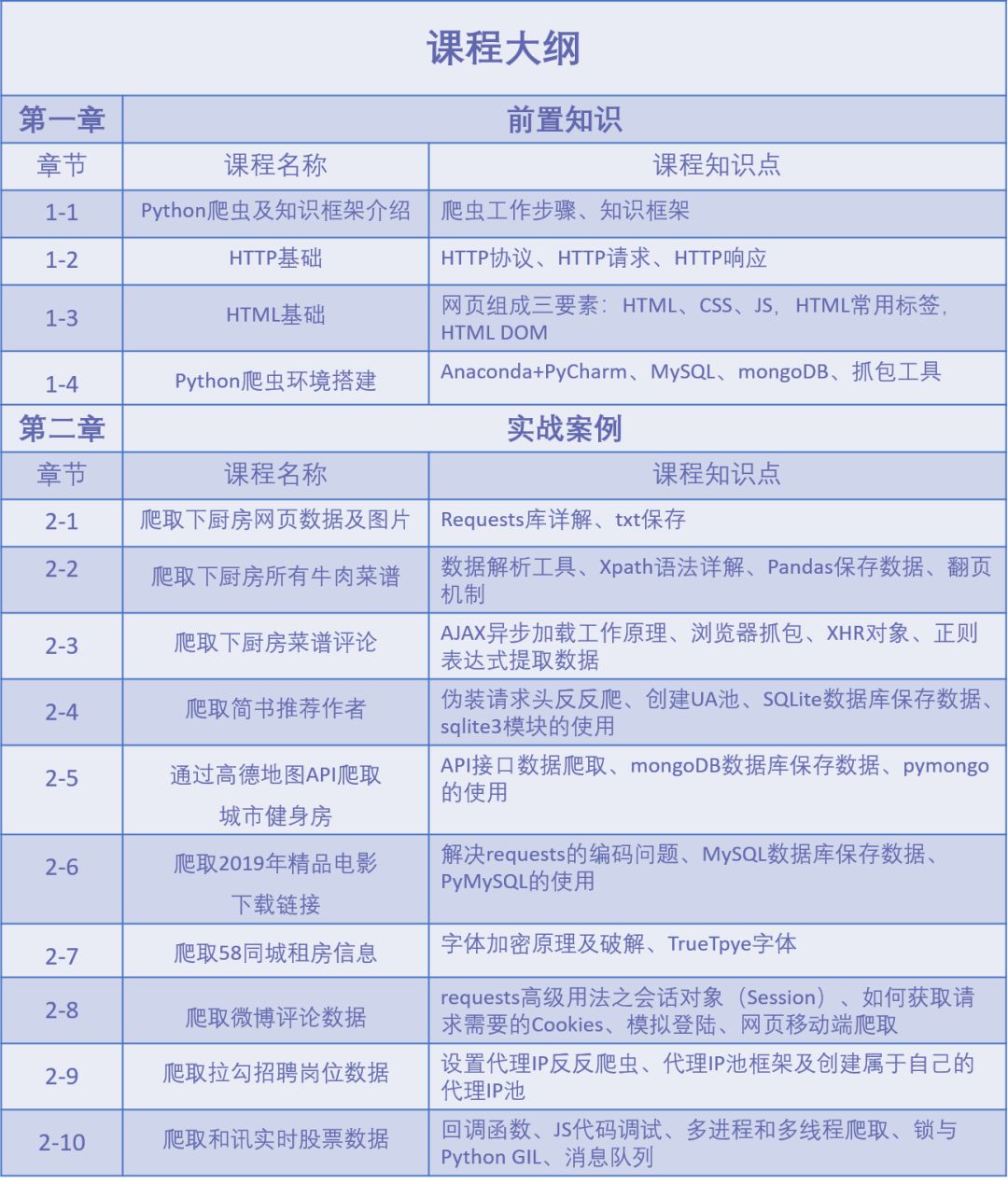
本次课程中所设计十个实战案例(案例包含爬取下厨房、简书、高德地图、电影天堂、58同城、微博、拉勾、和讯等网站,每个案例均包含数据获取、解析、储存三步走的完整爬虫流程)将Python爬虫涉及的所有知识点容纳其中,由浅入深,层层递进,让你在实战过程中养成爬虫思维,面对目标数据形成清晰爬虫思路,多种反反爬操作练习让你轻松举一反三。
你:课程从实战开始,我会不会听不懂,无从下手?
课程在开始辅以爬虫知识体系、HTTP基础、HTML基础以及Python爬虫运行环境搭建等基础知识,让小白也可以无痛入门Python爬虫。
同时,我们将通过案例详细讲解实现数据爬取所需要掌握的requests库请求方法,Xpath解析、正则表达式提取等数据解析方法;txt、Pandas、SQLite、MySQL、MongoDB等数据存储方法;AJAX异步加载、抓包、伪装请求头、创建UA池、字体加密、创建IP代理池、模拟登陆、JS调试等反反爬方法,多进程、多线程、消息队列等大规模爬取方法,让你学了就用,高效率获取课程知识点。
你:转行学习,看了许多教程,总感觉似懂非懂怎么办?
针对转行学习的同学,理论知识如果只是粗略讲一遍会难以理解,本课程使用丰富的结构图、流程图等来图解技术难点,将复杂的技术流程转换为直观的图形,形象化的表达让知识点更容易被理解。
同时,课程知识点设计根据老师实战经验删繁就简,比如在数据解析时,选用了速度快效率高的Xpath和正则表达式作为数据提取的主要方法,省去了一些爬虫课程中使用的提取速度慢的Beautiful Soup。并且结合以往的经验,大家由于没有HTML基础在学习Xpath语法时总是一脸懵,所以我们从HTML元素到HTML DOM树,再到Xpath语法,为大家规划了一条清晰的学习之路,让转行的同学也可以快速get要领。
你:我掌握这门课程后可以达到怎样的水平?
如果你是一个刚入门的数据分析爱好者,却苦于手头上没有数据进行实操,本课程将会带领你从基础知识入门,逐步掌握Python爬虫技术,获取到你想要的数据;
如果你是一名在校老师或学生,需要采集互联网数据为学术论文、毕业论文等写作作支撑,本课程可以带领你从最简洁的路径出发,快速掌握规模化采集互联网数据的方法;
如果你是一名运营人员或商业数据分析师,想要采集数据进行商业数据分析,发现数据中隐藏的商业信息,从而得出行之有效的商业决策,本课程可以让你掌握使用Python进行数据采集的方法,解决你的数据来源问题。
你:目前相关法律法规对于数据安全的管理越来越严格,使用Python爬虫采集数据会不会违反相关法律法规呀?
Python爬虫是一门数据采集的技术,它可以帮助我们快速地采集到数据,所以目前被应用到各行各业,比如说百度、谷歌等搜索引擎的底层数据采集使用的就是爬虫技术,很多公司也设置了专门的Python爬虫工程师岗位。我们只要合理利用Python爬虫去获取互联网上的公开数据,并且严格遵循爬虫的Robots协议和相关法律法规的规定,不违法获取个人隐私信息、不利用技术去触碰灰色产业链,就可以让Python爬虫正确地发光发热。
课程安排
师资介绍
深耕数据分析、挖掘领域多年,积累了丰富的项目开发与实战经验,专长于Python数据分析与挖掘、Spark大数据开发与分析。原某知名数据科学竞赛与学习平台课研经理及算法部负责人,具有丰富的数据分析、数据挖掘课程研发经验。
微信公众号【Alfred数据室】作者,曾撰写 “北上广深租房图鉴”,“周杰伦根本不需要流量”等热文,数据分析源代码同步分享在GitHub项目:interesting-python,该项目曾登上GitHub Trending热榜,目前已获得超过2500人标星。
以目标为导向,从实战出发,用一次次成功的项目经历让自己养成数据思维;
让问题引路,学填坑操作,告别盲目摸索,以一次次实战训练解决数据来源难题。
这是一门学了就能用的数据爬虫课程
目前享受新课首发优惠——无门槛30元优惠券
扫码可了解课程详情及试听课程

课程咨询,请扫码添加微信号:AlfredLabAssistant