点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转自3D视觉工坊。近期在学习SLAM中的回环检测模块,着重于对于字典的训练方式进行了研究,简单整理了下学习笔记如下。
一 DBoW库首先,DBoW库的作者github网址:
https://github.com/dorian3d?tab=overview&from=2018-12-01&to=2018-12-31
DBoW3是DBoW2的增强版,这是一个开源C++库,用于给图像特征排序,并将图像转化成视觉词袋表示。
DBoW3与DBoW2的主要差别:1、DBoW3可使用二值和浮点特征描述子,无需为任何描述符重写类;
2、DBoW3可以在Linux和Windows下编译;3、仍然和DBoW2中的yml文件兼容。
4、DBoW3依赖项只有OpenCV,DBoW2依赖项DLIB被移除;5、重写了代码进行优化,DBoW3的接口也被简化了;6、可使用二进制视觉词典文件,加载或者保存速度更快,而且,二进制文件还能被压缩;
同时,DoW3还生成一个图像数据库,带有顺序索引和逆序索引,可以使图像特征的检索和对比非常快。
二 ORB-SLAM2中的字典DBoW无论是DBoW2,还是DBoW3,我们发现它们封装的函数可以创建的字典文件格式都为yml格式,不能直接应用于不能直接应用于ORB-SLAM2,而ORB-SLAM2中的词典为ORBvoc.txt格式。
2.1 ORB-SLAM2中的ORBvoc.txt文件SLAM中的字典文件是作者使用非常庞大的图片库生成的,对室内和户外都有很好的效果,有时候自己生成的字典,由于我们采集的图片质量以及数据集没有他们那么庞大,效果不一定会比作者提供的好,其文件格式如下:10 6 0 0 #分别表示上面的树的分支、树的深度、相似度、权重0 0 252 188 188 242 169 109 85 143 187 191 164 25 222 255 72 27 129 215 237 16 58 111 219 51 219 211 85 127 192 112 134 34 0...#0表示节点的父节点;0表示是否是叶节点,是的话为1,否则为0;252-34表示orb特征;最后一位是权重。
2.2 DBoW3生成的yml文件格式首先我们来看一下yml格式的字典内容:vocabulary: k: 10 #表示树的分支 L: 5 #表示树的深度 scoringType: 0 #相似度 weightingType: 0 #权重 nodes:#节点,以下三个分别表示:节点id,父节点id,权重 - { nodeId:1, parentId:0, weight:0., descriptor:"0 32 62 65 18 172 93 223 86 104 133 132 233 11 79 219 43 144 216 249 195 98 76 35 26 140 179 213 1 63 115 63 110 130 " }- { nodeId:2, parentId:0, weight:0., descriptor:"0 32 254 180 252 240 173 125 80 203 219 191 181 57 78 253 78 159 143 215 237 16 62 103 235 211 219 219 85 127 195 108 78 71 " }... words: - { wordId:0, nodeId:31 } - { wordId:1, nodeId:32 } - { wordId:2, nodeId:33 }...
2.3 如何生成ORB-SLAM2中的ORBvoc.txt文件格式鉴于已经有作者对DBoW库进行了些许修改[1],在原有DBoW2库中加入一个模板函数saveToTextFile,使得可以直接生成ORB-SLAM2中开源代码提供的字典文件格式。同时,如果对于voc.txt文件的读取,需要在头文件TemplatedVocabulary.h中添加如下函数进行编译(这也是ORB-SLAM2开源代码作者实现好的函数),此处粘贴如下:template<class TDescriptor, class F>
bool TemplatedVocabulary<TDescriptor,F>::loadFromTextFile(const std::string &filename)
{
ifstream f;
f.open(filename.c_str());
if(f.eof())
return false;
m_words.clear();
m_nodes.clear();
string s;
getline(f,s);
stringstream ss;
ss << s;
ss >> m_k;
ss >> m_L;
int n1, n2;
ss >> n1;
ss >> n2;
if(m_k<0 || m_k>20 || m_L<1 || m_L>10 || n1<0 || n1>5 || n2<0 || n2>3)
{
std::cerr << "Vocabulary loading failure: This is not a correct text file!" << endl;
return false;
}
m_scoring = (ScoringType)n1;
m_weighting = (WeightingType)n2;
createScoringObject();
// nodes
int expected_nodes =
(int)((pow((double)m_k, (double)m_L + 1) - 1)/(m_k - 1));
m_nodes.reserve(expected_nodes);
m_words.reserve(pow((double)m_k, (double)m_L + 1));
m_nodes.resize(1);
m_nodes[0].id = 0;
while(!f.eof())
{
string snode;
getline(f,snode);
stringstream ssnode;
ssnode << snode;
int nid = m_nodes.size();
m_nodes.resize(m_nodes.size()+1);
m_nodes[nid].id = nid;
int pid ;
ssnode >> pid;
m_nodes[nid].parent = pid;
m_nodes[pid].children.push_back(nid);
int nIsLeaf;
ssnode >> nIsLeaf;
stringstream ssd;
for(int iD=0;iD<F::L;iD++)
{
string sElement;
ssnode >> sElement;
ssd << sElement << " ";
}
F::fromString(m_nodes[nid].descriptor, ssd.str());
ssnode >> m_nodes[nid].weight;
if(nIsLeaf>0)
{
int wid = m_words.size();
m_words.resize(wid+1);
m_nodes[nid].word_id = wid;
m_words[wid] = &m_nodes[nid];
}
else
{
m_nodes[nid].children.reserve(m_k);
}
}
return true;
}
三 TF-IDF在上述的字典中有个变量:scoringType,我们都知道scoring在英文中一般指评分的意思。那么在ORB字典里的评分是如何计算的呢?
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用加权技术。
TF-IDF是一种统计方法,用以评估——字词对于一个文件集或一个语料库中的某一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
3.1 TF——词频(Term Frequency)TF部分是指某个特征在单幅图像中出现的频率。假设图像M中单词wi出现了ni次,而一共出现的单词次数为n,则TFi计算公式如下:
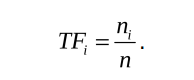
由以上公式也可看出,某单词在一幅图像中经常出现,它的区分度就越高。
3.2 IDF——逆文档频率(Inverse Document Frequency)我们统计某个叶子节点wi中的特征数量相对于所有特征数量的比例作为IDF部分。假设所有特征数量为n,wi数量为ni,那么该单词的IDFi为[2]:
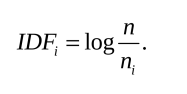
若IDFi=0,则表示该word的权重为0,也即每张图片上都有该word。若IDFi≠0,则我们希望该word在当前图像中出现的概率越高越好,那样就会有更好地区分度。
备注:在书[2]中这里给出的为log,但笔者也有点疑惑到底是以e为底还是以10为底取对数,对这个比较清楚的小伙伴也欢迎留言指教。注意:生成的词袋树只有IDF,没有TF。TF是对之后生成的词袋向量才会计算。
于是,单词wi的权重weightingType等于TF乘IDF之积:hi=TFi*IDFi
四 如何使用DBoW2训练字典首先可以下载个TUM开源数据集rgbd_dataset_freiburg1_plant,我们使用前十张图片用来训练字典。
第一步:编写程序读入图片;vector<string> vstrImageFilenames;
vector<double> vTimestamps;
string dataPath="../data/rgbd_dataset_freiburg1_plant";
string strFile_01=string(dataPath+"/rgb.txt");LoadImages(strFile_01,vstrImageFilenames,vTimestamps);
vector<Mat> images;
int nImages=vstrImageFilenames.size();
std::cout<<"image size == "<<nImages<<endl;
cv::Mat im;
for (int ni = 0; ni <nImages; ++ni)
{
string imgPath=string(dataPath+"/"+vstrImageFilenames[ni]);
std::cout<<"imgPath== "<<imgPath<<endl;
im=cv::imread(imgPath,CV_LOAD_IMAGE_UNCHANGED);
if(im.empty())
{
std::cerr<<endl<<"Failed to load image at:"
<<string(dataPath)<<"/"<<vstrImageFilenames[ni]<<endl;
return 1;
}
images.push_back(im);
}
其中,函数LoadImages用来读取数据集中的图片路径。void LoadImages(const string &strFile,vector<string> &vstrImageFilenames,vector<double> &vTimestamps)
{
ifstream f;
f.open(strFile.c_str());
while(!f.eof())
{
string s;
getline(f,s);
if(!s.empty())
{
stringstream ss;
ss<<s;
double t;
string sRGB;
ss>>t;
vTimestamps.push_back(t);
ss>>sRGB;
vstrImageFilenames.push_back(sRGB);
}
}
}第二步:检测ORB描述子;
cv::Ptr<cv::ORB> orb=cv::ORB::crate(1000,1.2,8,31,0,2,ORB::FAST_SCORE);
std::cout<<"Extracting ORB features... "<<endl;
for (int i = 0; i <images.size(); ++i)
{
cv::Mat mask;
vector<cv::KeyPoint> keypoints;
cv::Mat descriptors;
orb->detectAndCompute(images[i],mask,keypoints,descriptors);
features.push_back(vector<cv::Mat>());
changeStructure(descriptors,features.back());
}
其中,changStructure()函数源码如下:
void changeStructure(const cv::Mat &plain, vector<cv::Mat> &out)
{
out.resize(plain.rows);
for(int i = 0; i < plain.rows; ++i)
{
out[i] = plain.row(i);
}
}第三步:创建字典。
//Create Voc text
const int K=10;
const int L=5;
OrbVocabulary voc(K,L,TF_IDF,L1_NORM);
std::cout<<"Creating a "<<K<<"^"<<L<<" vocabulary..."<<endl;
voc.create(features);
std::cout<<"...done!"<<endl;
cout<<"Vocabulary information:"<<endl<<voc<<endl<<endl;
//save the vocabulary to disk
std::cout<<endl<<"Saving vocabulary... "<<endl;
voc.save("voc.yml.gz");
voc.saveToTextFile("MyVoc.txt");
cout<<"Done"<<endl;
经过以上步骤,我们即可以训练生成与ORB-SLAM2中提供的相同格式的字典了。那如何测试我们的字典是否可用呢?我们可以先选择一些带有回环的图片集,读取图片,之后,使用下面的程序步骤来进行计算相似度得分。
vector<vector<cv::Mat > > features;
features.reserve(imageVec.size());
cv::Ptr<cv::ORB> orb=cv::ORB::create(1000,1.2,8,31,0,2,ORB::FAST_SCORE);
for (int i = 0; i <imageVec.size(); ++i)
{
cv::Mat mask;
vector<cv::KeyPoint> keypoints;
cv::Mat descriptors;
orb->detectAndCompute(imageVec[i],mask,keypoints,descriptors);
features.push_back(vector<cv::Mat>());
LoopClosure::changeStructure(descriptors,features.back());
}
cout<<"Creating a database..."<<endl;
//load the vocabulary from disk
OrbVocabulary voc;
voc.loadFromTextFile("../data/OwnVoc/MyVoc.txt");
//voc.loadFromTextFile("../data/ORBVoc/ORBvoc.txt");
OrbDatabase db(voc,false,0); //false=do not use direct index
// (so ignore the last param)
// The direct index is useful if we want to retrieve the features that
// belong to some vocabulary node.
// db creates a copy of the vocabulary, we may get rid of "voc" now
//add images to the database
for(int i=0;i<features.size();i++)
{
db.add(features[i]);
}
cout<<"Database information: "<<endl<<db<<endl;
//and query the database
cout<<"Querying the database: "<<endl;
DBoW2::QueryResults ret;
for(int k=0;k<features.size();k++)
{
cout<<endl<<endl;
cout<<"k== "<<k<<endl;
db.query(features[k],ret,10);
cout<<"Searching for Image"<<k<<". "<<ret<<endl;
}
通过上述步骤,便可以使用我们自己生成的字典来计算图片之间的相似度得分了,运行结果部分截图如下:
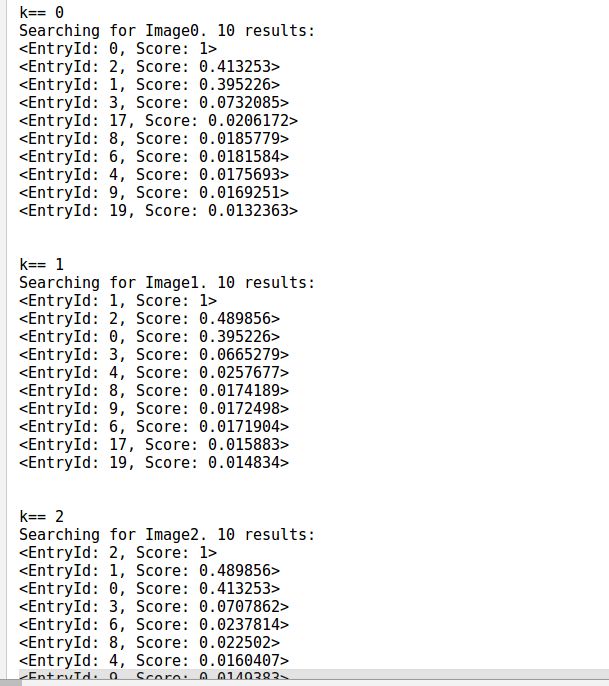
五 跋最后,留给大家一个问题:如何判断我们自己生成的字典与ORB-SLAM2作者提供的字典效果哪个效果更好呢?欢迎小伙伴们讨论交流。
参考文献[1] 简书博文:
https://www.jianshu.com/p/cfcdf12a3bb6
[2] 高翔 张涛 《视觉SLAM十四讲》
从零开始学习三维视觉核心技术SLAM,扫描查看介绍,3天内无条件退款

早就是优势,学习切忌单打独斗,这里有教程资料、练习作业、答疑解惑等,优质学习圈帮你少走弯路,快速入门!
交流群欢迎加入公众号读者群一起和同行交流,目前有SLAM、算法竞赛、检测分割识别、三维视觉、医学影像、自动驾驶、计算摄影等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

推荐阅读前段时间参加了个线下交流会(附SLAM入门视频)
从零开始一起学习SLAM | 为什么要学SLAM?
从零开始一起学习SLAM | 学习SLAM到底需要学什么?
从零开始一起学习SLAM | SLAM有什么用?
从零开始一起学习SLAM | C++新特性要不要学?
从零开始一起学习SLAM | 为什么要用齐次坐标?
从零开始一起学习SLAM | 三维空间刚体的旋转
从零开始一起学习SLAM | 为啥需要李群与李代数?
从零开始一起学习SLAM | 相机成像模型
从零开始一起学习SLAM | 不推公式,如何真正理解对极约束?
从零开始一起学习SLAM | 神奇的单应矩阵
从零开始一起学习SLAM | 你好,点云
从零开始一起学习SLAM | 给点云加个滤网
从零开始一起学习SLAM | 点云平滑法线估计
从零开始一起学习SLAM | 点云到网格的进化
从零开始一起学习SLAM | 理解图优化,一步步带你看懂g2o代码
从零开始一起学习SLAM | 掌握g2o顶点编程套路
从零开始一起学习SLAM | 掌握g2o边的代码套路
从零开始一起学习SLAM | ICP原理及应用
从零开始一起学习SLAM | 用四元数插值来对齐IMU和图像帧
可视化理解四元数,愿你不再掉头发
视觉SLAM技术综述
研究SLAM,对编程的要求有多高?
现在开源的RGB-D SLAM有哪些?
详解 | SLAM回环检测问题
汇总 | SLAM、重建、语义相关数据集大全
吐血整理 | SLAM方向国内有哪些优秀的公司?
最强战队 | 三维视觉、SLAM方向全球顶尖实验室汇总
SLAM方向公众号、知乎、博客上有哪些大V可以关注?
汇总 | 最全 SLAM 开源数据集
综述 | SLAM回环检测方法
干货总结 | SLAM 面试常见问题及参考解答
2019 最新SLAM、定位、建图求职分享,看完感觉自己就是小菜鸡!
2019暑期计算机视觉实习应聘总结2018年SLAM、三维视觉方向求职经验分享
经验分享 | SLAM、3D vision笔试面试问题
最新AI干货,我在看



