背景
现在我们学院正在尝试让同学们在一个在线的教学平台中提交笔译作业,有老师提出:可否增加一个学生翻译作业抄袭检测的功能,借此可以看出某次作业哪些同学的作业是相似的。
这个功能我基本上开发完了,我准备通过这篇文章介绍一下这个功能实现的大致过程和效果。
正文
示例学生译文

在以上给出的示例中,第一列是每个学生唯一的ID,第二列是一句英文对应的学生译文。
我们的目的是发现在类似这种形式的一句多译学生翻译作业中,有没有同学有相互抄袭的情况。
一
为了演示方便,我们虚拟一组翻译作业的译文,如下代码:
<?php
$A = "我爱你中国";$B = "中国我爱你";$C = "我爱你祖国";$D = "祖国我爱你";$E = "我爱你中国";?>
接下来,我们希望计算这五句话互相之间的相似度,并且把获取到的相似度的结果存储到一个表中,如下表:
StartABCDEA
B
C
D
E
我使用的编程语言是PHP,其中有一个函数叫similar_text(),可以用来计算相似度,还有一个函数叫round(),可以把相似度的结果四舍五入。
以下是计算相似度的代码:
<?php$A = "我爱你中国";$B = "中国我爱你";$C = "我爱你祖国";$D = "祖国我爱你";$E = "我爱你中国";
similar_text($A,$B,$percent);echo round($percent);?>
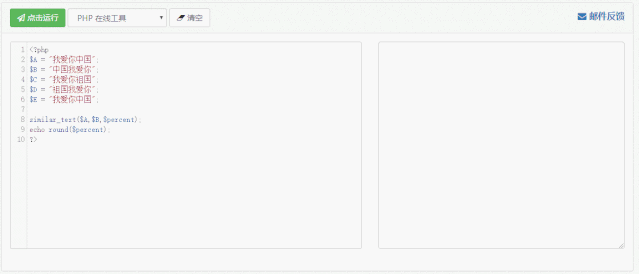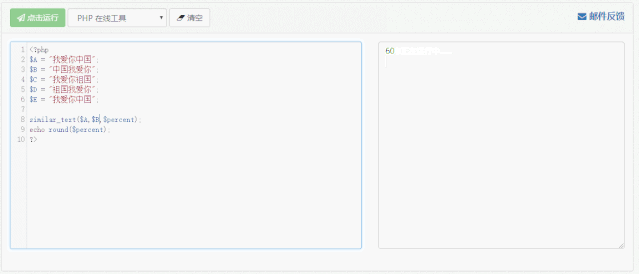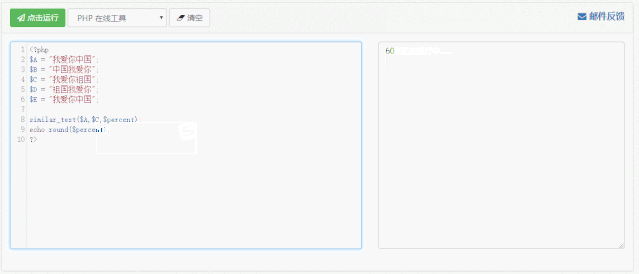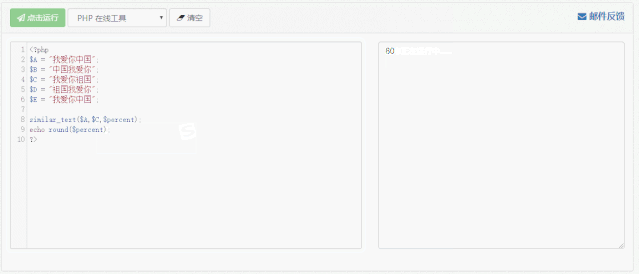
通过这段代码我们可以逐一计算每两句话之间的相似度,并且将其填入表中。
我们可以首先填入每个句子和自己之间的相似度,必定是100:
StartABCDEA100
B
100
C
100
D
100
E
100
然后从A句开始,逐步和B、C、D、E比较:
StartABCDEA100608060100B
100
C
100
D
100
E
100
但是,在比较A和B的时候,得到的相似度计算结果实际上也是B和A之间的结果,所以,我也可以把相应的结果填入到左下角中,如下表:
StartABCDEA100608060100B60100
C80
100
D60
100
E100
100
然后再从B开始,计算与C、D、E之间的相似度:
StartABCDEA100608060100B60100608060C80
100
D60
100
E100
100
计算完之后同样可以得到C与B、D与B、E与B之间的相似度:
StartABCDEA100608060100B60100608060C8060100
D6080
100
E10060
100
以此类推,我们可以得到全部的相似度计算结果:
StartABCDEA100608060100B60100608060C80601006080D60806010060E100608060100
以上是我们获得的所有句子相互之间的相似度。
通过上面的分析可以看出,实际上我们在做抄袭检测的时候真正要计算的只不过是上面的表格中一部分的内容,即下表中加粗标红的部分:
StartABCDEA100608060100B60100608060C80601006080D60806010060E100608060100
假如我们给这个表格中所有的内容标上“坐标值”,如下图:
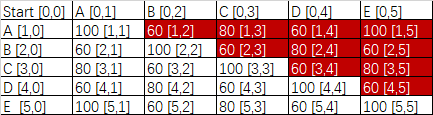
仔细观察这个有标注的表格,我们用两个数字来标注每一个单元格,第一个数字代表“行”,第二个数字代表“列”,每一行和每一列都从“0”开始数,所以A和A之间的相似度“100”位于第1行的第1列。
如果再仔细观察一下,会发现:所有标红的单元格都有一个特点:
第一个数字要小于第二个数字。
也就是说,我们在这样一个表格中,我们只需要去计算第0行以下和第0列以右的所有单元格中行数小于列数的单元格。
二
接下来,我们就看看代码怎么写。
第一步:将要计算相似度的所有译文及其学生ID放到一个表中
为了计算方便,我们可以将学生的译文及学生ID做成这样一个表:
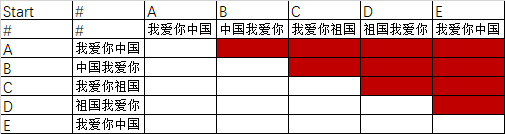
以下是代码:
<?php$translations = array( 0 => array ( "id" => "A", "text" => "我爱你中国" ), 1 =>array ( "id" => "B", "text" => "中国我爱你" ), 2 =>array ( "id" => "C", "text" => "我爱你祖国" ), 3 =>array ( "id" => "D", "text" => "祖国我爱你" ), 4 =>array ( "id" => "E", "text" => "我爱你中国" ));
$matrix = array();
$num = count($translations);
for ( $i=0; $i < $num; $i++) { $matrix[0][$i+2] = $translations[$i]["id"]; $matrix[1][$i+2] = $translations[$i]["text"]; $matrix[$i+2][0] = $translations[$i]["id"]; $matrix[$i+2][1] = $translations[$i]["text"]; }
var_dump($matrix);?>
上面代码的运行结果是:
array(7) { [0]=> array(5) { [2]=> string(1) "A" [3]=> string(1) "B" [4]=> string(1) "C" [5]=> string(1) "D" [6]=> string(1) "E" } [1]=> array(5) { [2]=> string(15) "我爱你中国" [3]=> string(15) "中国我爱你" [4]=> string(15) "我爱你祖国" [5]=> string(15) "祖国我爱你" [6]=> string(15) "我爱你中国" } [2]=> array(2) { [0]=> string(1) "A" [1]=> string(15) "我爱你中国" } [3]=> array(2) { [0]=> string(1) "B" [1]=> string(15) "中国我爱你" } [4]=> array(2) { [0]=> string(1) "C" [1]=> string(15) "我爱你祖国" } [5]=> array(2) { [0]=> string(1) "D" [1]=> string(15) "祖国我爱你" } [6]=> array(2) { [0]=> string(1) "E" [1]=> string(15) "我爱你中国" }}
为了理解上面这段代码,我们可以再观察一下这张表:
如果给这个图加上数字序号,就可以更清楚知道我们要计算的是哪个单元格的值,如下图:

由上图可知,我们需要把学生译文分别放到:
[1,2] [1,3] [1,4] [1,5] [1,6] 这五个单元格中
和
[2,1]
[3,1]
[4,1]
[5,1]
[6,1]
这五个单元格中。
我们看一下ID等于“A”的“我爱你中国”,在第2行中,它需要放到[1,2]这个单元格中,它的ID“A”需要放到[0,2]这个单元格中。
而“我爱你中国”在$translations这个变量中的位置又是[0]["text"],它的ID“A”在$translations这个变量中的位置是[0]["id"]。
因此,要想把“我爱你中国”从一个数组转移到另一个数组中,就需要进行以下操作:
$matrix[0][2] = $translations[0]["id"]; $matrix[1][2] = $translations[0]["text"];
相应的,放到第二列时,ID和“我爱你中国”要分别放到[2,0]和[2,1]这两个单元格中,所以需要进行以下操作:
$matrix[2][0] = $translations[0]["id"]; $matrix[2][1] = $translations[0]["text"];
不过这只是一个译文的操作,涉及到全部译文,就需要用循环来完成,而且这个循环的运行次数还得考虑译文的次数,所以才有了以下代码:
$num = count($translations);
for ( $i=0; $i < $num; $i++) { $matrix[0][$i+2] = $translations[$i]["id"]; $matrix[1][$i+2] = $translations[$i]["text"]; $matrix[$i+2][0] = $translations[$i]["id"]; $matrix[$i+2][1] = $translations[$i]["text"]; }这个循环从$i=0开始,当$i=0时,对应的就是ID等于A的“我爱你中国”的相应操作。
每处理完一个译文,$i的值就会自增1($i++)。
在这个循环中$num的值是5,因为一共有5个译文。当$i=4时,4 <5,循环运行的条件还成立,这个时候运行的代码就是:
$matrix[0][6] = $translations[4]["id"]; $matrix[1][6] = $translations[4]["text"];
$matrix[6][0] = $translations[4]["id"]; $matrix[6][1] = $translations[4]["text"];
恰好就完成了最后一个译文的操作,自此实现全部译文从数组$translations转换到数组$matrix中。
三
当我们将全部译文成功放到了数组$matrix中后,我们接下来就可以在这个数组中进行计算了,代码如下:
for ($i = 0; $i < $num-1; $i++){ $up = $matrix[1][$i+3]; for($j = 0; $j < $num-1; $j++) { $down = $matrix[$j+2][1]; if($j+2 < $i+3) { similar_text($up,$down,$percent); $matrix[$j+2][$i+3] = round($percent); } }}
乍看这段代码很突兀,但仔细分析就会明白道理:
我们首先来看如何计算第二行中ID等于B的“中国我爱你”和第二列中ID等于A的“我爱你中国”之间的相似度。
他们的“坐标”分别是:[1,3]和[2,1],如下图所示:

所以在$matrix中我要计算的就是:
$matrix[1][3]和$matrix[2][1]
两个值之间的相似度。
我可以用两个变量分别表示他们:
$up = $matrix[1][3];$down = $matrix[2][1];
同样的,因为有很多译文,所以我们需要用循环来完成运算,但这个循环比较特殊,需要用嵌套循环。
第一个循环用于遍历读取“行”中的所有译文,而且每读取一个译文,就要分别把这个译文同“列”中的译文进行相似度计算,而“列”中的数据又需要一个循环来遍历,所以我们才需要把两个循环嵌套在一起去使用。
for ($i = 0; $i < $num-1; $i++) //循环一{ $up = $matrix[1][$i+3]; for($j = 0; $j < $num-1; $j++) //循环二 { $down = $matrix[$j+2][1]; }}
大家再回顾一下我们在本文第一部分得到的结论:
我们只需要去计算第0行以下和第0列以右的所有单元格中行数小于列数的单元格。
也就是说像[3,3]、[4,3]这种单元格,我们都不需要去计算:

所以我们必须要告诉程序这种情况,如下代码:
for ($i = 0; $i < $num-1; $i++){ $up = $matrix[1][$i+3]; for($j = 0; $j < $num-1; $j++) { $down = $matrix[$j+2][1]; if($j+2 < $i+3) //判断是否列值小于行值 { similar_text($up,$down,$percent); $matrix[$j+2][$i+3] = round($percent); } }}
最后一个要解决的问题就是循环的条件,究竟什么时候循环停止。
在我们给大家提供的例子中,算完[5,6]这个单元格就停止,也就是算[1,6]和[5,1]这两个值间的相似度。
由于我们算的第一个值是“$up = $matrix[1][$i+3]; ”和“ $down = $matrix[$j+2][1];”,意味着,我们算的最后一个值应该是:
“$up = $matrix[1][3+3]; ”和“$down = $matrix[3+2][1];”
所以循环运行的终止条件应该是$i < 4。
所以我们选择了$i < $num -1作为循环运行的终止条件,$num是译文的数量,这个例子中是5。
由此,我们就可以获得全部译文之间的相似度。代码运行之后,得到的$matrix内容为:
array(7) { [0]=> array(5) { [2]=> string(1) "A" [3]=> string(1) "B" [4]=> string(1) "C" [5]=> string(1) "D" [6]=> string(1) "E" } [1]=> array(5) { [2]=> string(15) "我爱你中国" [3]=> string(15) "中国我爱你" [4]=> string(15) "我爱你祖国" [5]=> string(15) "祖国我爱你" [6]=> string(15) "我爱你中国" } [2]=> array(6) { [0]=> string(1) "A" [1]=> string(15) "我爱你中国" [3]=> float(60) [4]=> float(80) [5]=> float(60) [6]=> float(100) } [3]=> array(5) { [0]=> string(1) "B" [1]=> string(15) "中国我爱你" [4]=> float(60) [5]=> float(80) [6]=> float(60) } [4]=> array(4) { [0]=> string(1) "C" [1]=> string(15) "我爱你祖国" [5]=> float(60) [6]=> float(80) } [5]=> array(3) { [0]=> string(1) "D" [1]=> string(15) "祖国我爱你" [6]=> float(60) } [6]=> array(2) { [0]=> string(1) "E" [1]=> string(15) "我爱你中国" }}
这个结果与我们手算的结果是一致的:
StartABCDEA100608060100B60100608060C80601006080D60806010060E100608060100
为了得到涉嫌抄袭的学生的ID,我们还需要把相似度等于100的学生ID显示出来,以下为修改之后的代码:
<?php
$translations = array( 0 => array ( "id" => "A", "text" => "我爱你中国" ), 1 =>array ( "id" => "B", "text" => "中国我爱你" ), 2 =>array ( "id" => "C", "text" => "我爱你祖国" ), 3 =>array ( "id" => "D", "text" => "祖国我爱你" ), 4 =>array ( "id" => "E", "text" => "我爱你中国" ));$matrix = array();
$num = count($translations);
for ( $i=0; $i < $num; $i++) { $matrix[0][$i+2] = $translations[$i]["id"]; $matrix[1][$i+2] = $translations[$i]["text"]; $matrix[$i+2][0] = $translations[$i]["id"]; $matrix[$i+2][1] = $translations[$i]["text"]; }
for ($i = 0; $i < $num-1; $i++){ $up = $matrix[1][$i+3]; for($j = 0; $j < $num-1; $j++) { $down = $matrix[$j+2][1]; if($j+2 < $i+3) { similar_text($up,$down,$percent); $matrix[$j+2][$i+3] = round($percent); if(round($percent) == 100) { echo "学生".$matrix[0][$i+3]."和学生".$matrix[$j+2][0]."可能存在抄袭。"; echo "他们的译文分别是:".$matrix[1][$i+3]."和".$matrix[$j+2][1]."。"; } } }}var_dump($matrix);?>
代码输出的结果为:
学生E和学生A可能存在抄袭。他们的译文分别是:我爱你中国和我爱你中国。
我们在这里把抄袭定性为相似度为100。实际上也可以定得更低,比如:大于79,结果如下:
学生C和学生A可能存在抄袭。他们的译文分别是:我爱你祖国和我爱你中国。
学生D和学生B可能存在抄袭。他们的译文分别是:祖国我爱你和中国我爱你。
学生E和学生A可能存在抄袭。他们的译文分别是:我爱你中国和我爱你中国。
学生E和学生C可能存在抄袭。他们的译文分别是:我爱你中国和我爱你祖国。
以上就是一种学生间翻译作业抄袭检测小工具的实现方法,仅供大家参考。而这种方法也可以用于计算一篇文章中的内部重复,用于在翻译前提前抽取出那些相似的句子先翻译。


